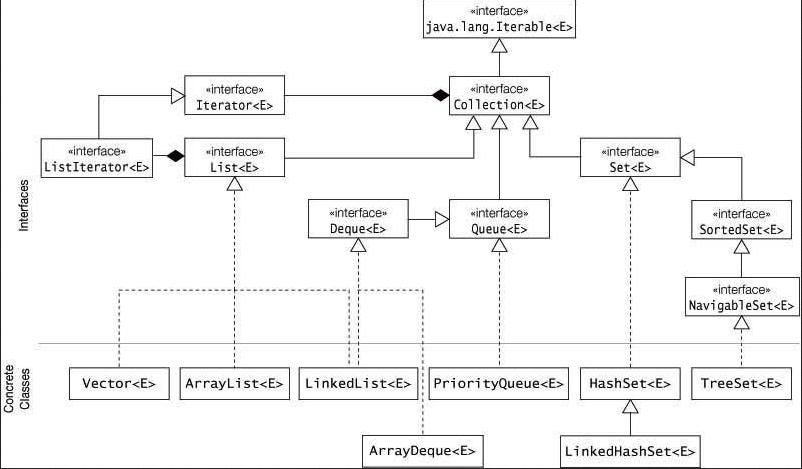
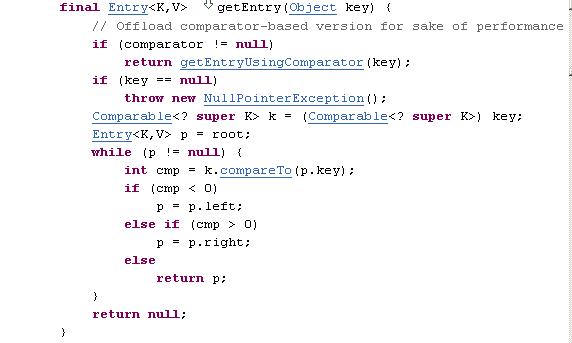
package mailer.notification;
public class NotificationTask {
private String msgBody;
private String to;
public NotificationTask(String msgBody, String to) {
super();
this.msgBody = msgBody;
this.to = to;
}
public String getMsgBody() {
return msgBody;
}
public void setMsgBody(String msgBody) {
this.msgBody = msgBody;
}
public String getTo() {
return to;
}
public void setTo(String to) {
this.to = to;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return getMsgBody() + "-" + getTo();
}
}
A Deleivery Mode
package mailer;
public enum DeliveryMode {
Urgent,
Normal;
}
A NotificationTypeEnunm
package mailer;
public enum NotificationType {
HTML_MAIL,
MAIL,
SMS;
}
A NotificationMessage
package mailer;
public class NotificationMessage<T> implements Comparable<NotificationMessage<T>>{
private T notificationObject;
private NotificationType type;
private DeliveryMode deliveryMode;
public NotificationMessage(T notificationObject,
NotificationType type, DeliveryMode deliveryMode) {
super();
this.notificationObject = notificationObject;
this.type = type;
this.deliveryMode = deliveryMode;
}
public NotificationMessage(T notificationObject, NotificationType type) {
super();
this.notificationObject = notificationObject;
this.type = type;
this.deliveryMode = DeliveryMode.Urgent;
}
public T getNotificationObject() {
return notificationObject;
}
public void setNotificationObject(T notificationObject) {
this.notificationObject = notificationObject;
}
public NotificationType getType() {
return type;
}
public void setType(NotificationType type) {
this.type = type;
}
public DeliveryMode getDeliveryMode() {
return deliveryMode;
}
public void setDeliveryMode(DeliveryMode deliveryMode) {
this.deliveryMode = deliveryMode;
}
@Override
public int compareTo(NotificationMessage<T> o) {
// TODO Auto-generated method stub
if(o.getDeliveryMode()!=this.getDeliveryMode()){
if(o.getDeliveryMode()==DeliveryMode.Urgent){
return 1;
}else
return -1;
}
return 0;
}
}
A MailerService
package mailer;
public interface MailerService<T> {
void sendMessage(NotificationMessage<T> message);
}
MailerServiceImpl
package mailer;
import java.util.concurrent.PriorityBlockingQueue;
/**
* This implementation will receive the Notification message
* and add it to the blocking priority queue
*
* This blocking priority queue will be read the a same implementation here that will invoke
* different implementations based on the notification message type
*
* @author tkuma6
*
* @param <T>
*/
public class MailerServiceImpl<T> implements MailerService<T>{
public PriorityBlockingQueue<NotificationMessage<T>> queue = new PriorityBlockingQueue<NotificationMessage<T>>(10);
MailerServiceImpl(){
Thread t = new Thread(new MessageConsumer(queue));
t.start();
}
@Override
public void sendMessage(NotificationMessage<T> message) {
if(queue!=null){
queue.add((NotificationMessage<T>) message);
return;
}
throw new RuntimeException("Broker not intialized");
}
class MessageConsumer implements Runnable{
PriorityBlockingQueue<NotificationMessage<T>> queueConsumer;
public MessageConsumer(PriorityBlockingQueue<NotificationMessage<T>> queue){
this.queueConsumer = queue;
}
@Override
public void run() {
System.out.println(queueConsumer);
while(true){
NotificationMessage<T> notifier;
try {
notifier = queueConsumer.take();
System.out.println(notifier.getNotificationObject());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("hi");
}
}
}
}
TestMailer
package mailer;
import mailer.notification.NotificationTask;
public class TestMailer {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
MailerService<NotificationTask> mailerService = new MailerServiceImpl<NotificationTask>();
for(int i=0;i<10;i++){
if(i%2 ==0){
mailerService.sendMessage(new NotificationMessage<NotificationTask>(new NotificationTask("URGENT test-" +i ,"URGENT testTo-"+ i), NotificationType.HTML_MAIL));
}else{
mailerService.sendMessage(new NotificationMessage<NotificationTask>(new NotificationTask("test-" +i ,"testTo-"+ i), NotificationType.HTML_MAIL));
}
}
}
}